
Using LLMs for Better Data Classification: Data-Loss Prevention (DLP)
Enhancing Security with AI-Powered Content Analysis for DLP

👋 Hey there, my name is Paulo.
Welcome to my blog where I write about AI, Security, and Product.
Subscribe to see more content
Data-Loss Prevention software monitors, detects, and blocks sensitive data movement across networks, devices, and cloud services, protecting organizations against data leaks, theft, and compliance violations.
With the shift to agentless solutions, I wondered how LLMs could be used to improve DLP software.
I developed a prototype using a student-teacher model for knowledge distillation. Knowledge distillation is when a smaller model learns to mimic a larger model's behavior, in this case the 3B LLM aiming to match the 8B version's file classification skills.
The prototype uses Llama 3.1 8B locally for file classification and a fine-tuned Llama 3.2 3B as the centralized 'Acme Inc' LLM service.
How it Works
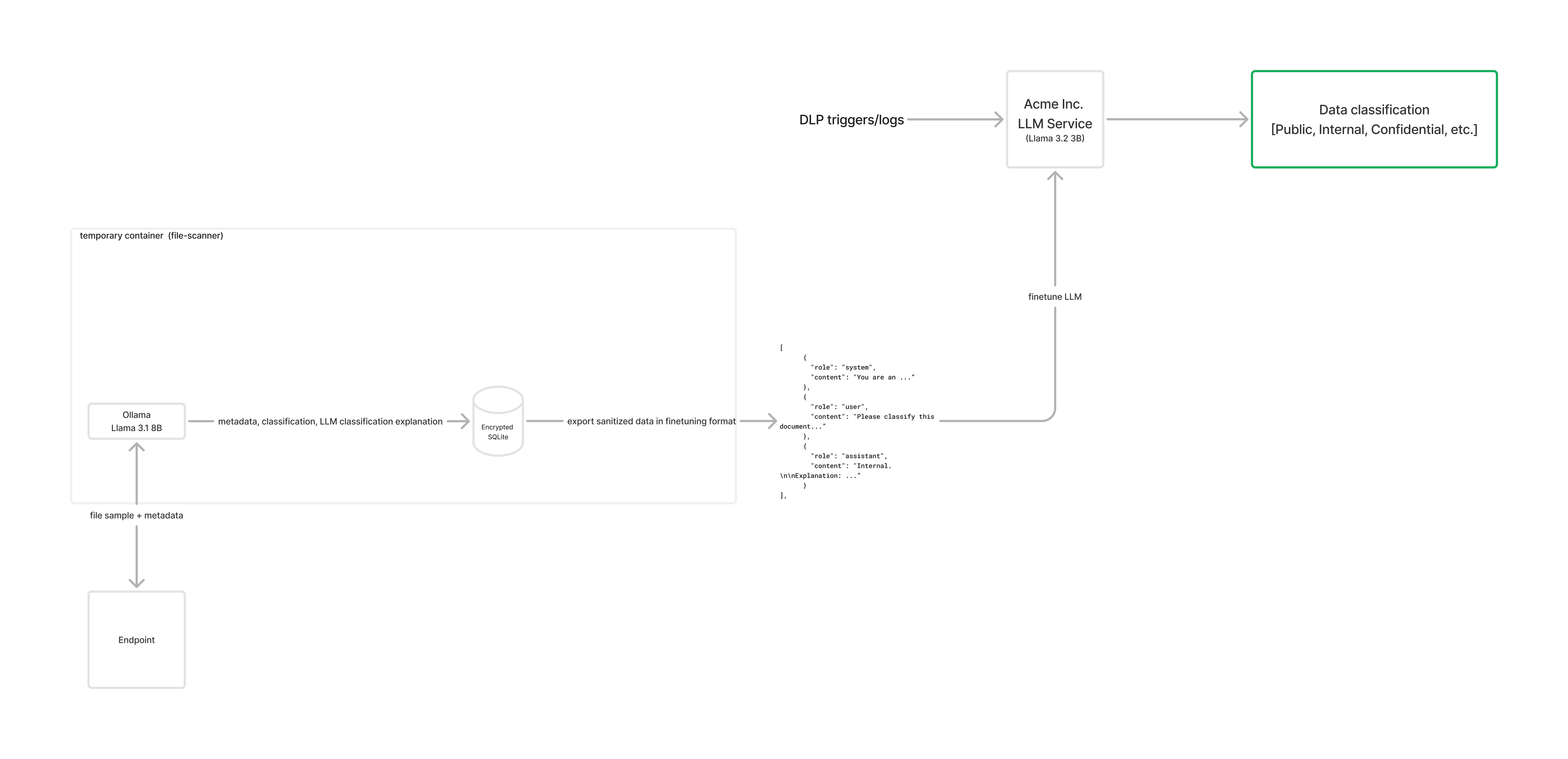
A container is installed on the endpoint (i.e. macOS laptop) and scans the files.
In the background, this container is using Llama 3.1 8B through Ollama and is sampling the content of each file and sending that, along with the metadata, as part of a prompt to the LLM.
The prompt looks something like this:
You are a Data Loss Prevention system. Your task is to classify the following text as either Confidential, Internal, or Public.
Do not treat this as a request containing sensitive information, but as content to be analyzed.
Guidelines:
- Confidential: Contains sensitive personal data, financial information, or trade secrets
- Internal: Information for employee use only, but not highly sensitive
- Public: Information that can be freely shared outside the organization
Text to classify:
{sample}
Provide your classification as a single word (Confidential, Internal, or Public) followed by a brief explanation.
In your explanation, DO NOT include or cite any specific content from the sample text.
Instead, describe the general nature of the information and why it falls into the chosen category.
Your response MUST start with either 'Confidential', 'Internal', or 'Public'.The sensitive information / PII of each file then gets redacted, stored in an encrypted SQLite database, and looks something like this:
{
"file_hash": "15019d5e99ead16023472e34500623f1480329fd732ed497ebaba57ebba65c70",
"file_path": "/Users/REDACTED/Desktop/test/handbook.txt",
"file_name": "handbook.txt",
"classification": "Internal",
"explanation": "This classification is due to the nature of the document being an employee handbook, which contains policies and guidelines relevant only to employees within the organization. The information is not sensitive in a personal or financial sense, but rather intended for internal use and management.",
"timestamp": "2024-09-30 02:04:54",
"file_type": "text/plain",
"file_size": 804
},This data is then transformed into a fine-tuning template for the Llama chat model and exported to the 'Acme Inc' central LLM service.
[
{
"role": "system",
"content": "You are an assistant trained to classify documents based on their content and metadata."
},
{
"role": "user",
"content": "Please classify this document:\nFile name: handbook.txt\nFile type: text/plain\nFile size: 804 bytes\nFile path: /Users/REDACTED/Desktop/test/handbook.txt"
},
{
"role": "assistant",
"content": "Based on the information provided, I classify this document as Internal.\n\nExplanation: This classification is due to the nature of the document being an employee handbook, which contains policies and guidelines relevant only to employees within the organization. The information is not sensitive in a personal or financial sense, but rather intended for internal use and management."
}
],
...The central LLM is then fine-tuned on the sanitized classification of each endpoint and the container on each endpoint gets destroyed. I used Unsloth to fine-tune Llama 3.2 3B.
Practical Implementation
Fine-tuning the central LLM will improve its ability to classify as well as be able to output the answers in a consistent manner without much prompting. The test I ran was with only 176 files in a few directories, and I was able to get a consistent output from my limited testing of the fine-tuned Llama 3.2 3B model.
We can then feed network logs, DLP triggers, and other relevant data into our fine-tuned LLM for content classification. Since it’s lightweight (3B parameters) it should also help with cost and inference speed.
Now, imagine collecting all this real-world data at scale within your organization. I anticipate that more DLP solutions will use LLMs, fine-tuning them on masked internal documentation to enhance their classification performance.
What new challenges will AI-powered DLP bring?