
The Future of Agents: Will AI Agents Replace Classic Workflow Automation?
A Look at the Future of AI-native Automation


This post was co-authored with Dex from HumanLayer, thanks for the feedback and sketches for this post!
As AI agents evolve, will they render classic workflow automation obsolete, or will bottlenecks in scaling laws, data, and computation keep traditional systems relevant?
We’ve been spending a lot of time chatting about this, and here is what we have figured out so far.
Background Context
If technology continues evolving at its current rate, here’s where I think agents will be in two years.
What Are “Agents”?
2024 was the year we spent way too much time arguing about “what it means to be an agent” and “it’s not an agent unless it …”. When I refer to “agents,” I mean LLMs paired with tools that independently make decisions and perform actions.
The Emergence of Chain of Thought (CoT) Reasoning / Test-time Compute in Models
We are starting to see models like o1 and o3, which have Chain of Thought (CoT) reasoning built into them through test-time compute. Test-time compute essentially allows a model to spend more time exploring different solutions and reasoning to arrive at the most accurate answer. This enables more reliable LLM outputs and better reasoning for advanced workflows.
This development will allow “agents” to think with greater trust and accuracy as they explain their thought processes, moving that logic out of the framework and behind the model API. We can implement human-in-the-loop for critical chain of thought steps and use that human feedback for post-training to enhance the agent’s performance.
Early Indicators of Adoption: Cursor Composer
It might sound ambitious for this to be adopted at scale, but we’re already seeing early indications of it. Take Cursor Composer, for example it essentially writes code for you, applies it to the appropriate files in your codebase, and waits for your approval before implementing changes. For something as sensitive as code—where mistakes could be catastrophic—this demonstrates that users are increasingly willing to trust these systems.
The Staggered Adoption of “Agents”

Whether you’re writing simple Python scripts or deploying to a sophisticated workflow orchestrator like Celery, Airflow, Prefect, or hundreds of others, almost any software can be represented as a directed graph (DG). Later, when traditional ML took off, we started to see some non-deterministic steps for summarizing, classifying, and maybe even determining the next step in a graph.
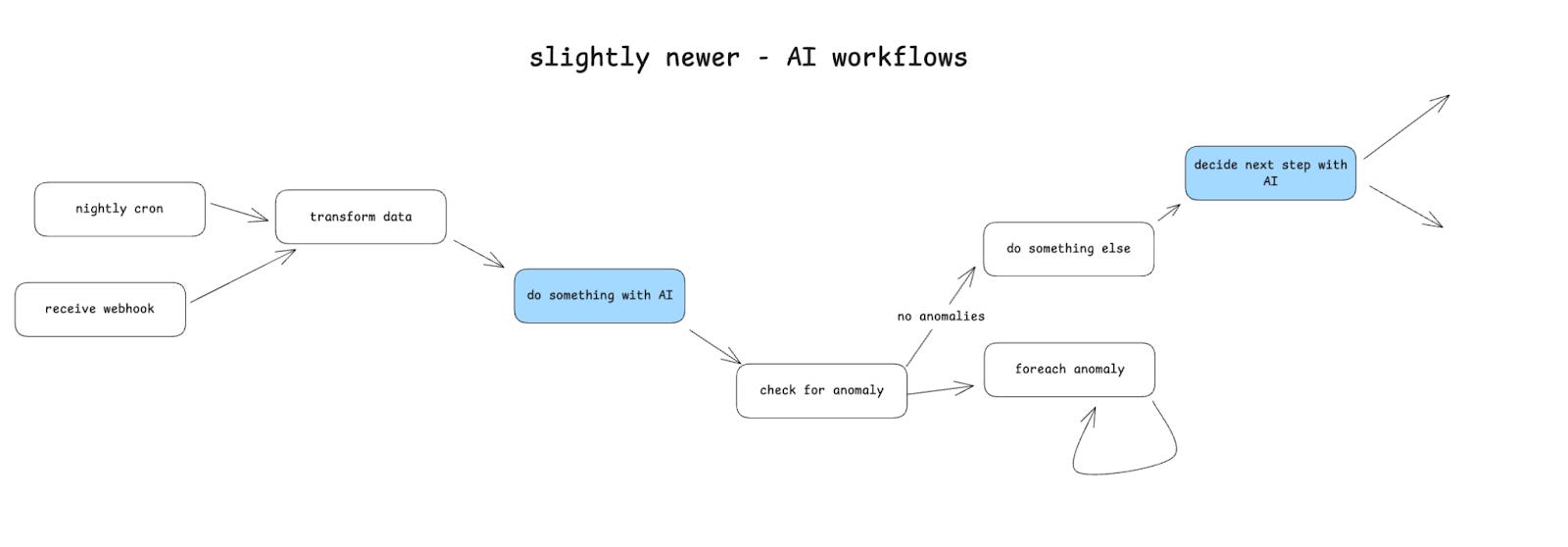
The Promise of Agents

One basic definition of AI Agents is the generalization of this node from the workflow above.
If an LLM can decide what the next step in any given workflow is, then maybe we don’t need to code up the DAG at all - we can just say “here’s your prompt, here’s a bunch of tools, go figure it out”.

This is the core of the ReAct Agent paper - think about what to do, do it, and decide if we’re done, otherwise, pick the next action.
I think "agent" adoption will follow a staggered distribution. Early versions (as we’re seeing now) likely utilize DAGs and traditional ML classification models for lightweight tasks, such as routing functions to the appropriate agent.
The Problem
Current Agent Complexity Challenges

Fully autonomous agents don’t yet function effectively in production because, when you have, say, 30-50 tools being passed to your LLM, it cannot reliably determine which tool to route to, especially after several turns. This not only reduces accuracy but also increases inference costs over time due to the extensive CoT reasoning required by agents.
What Actually Works
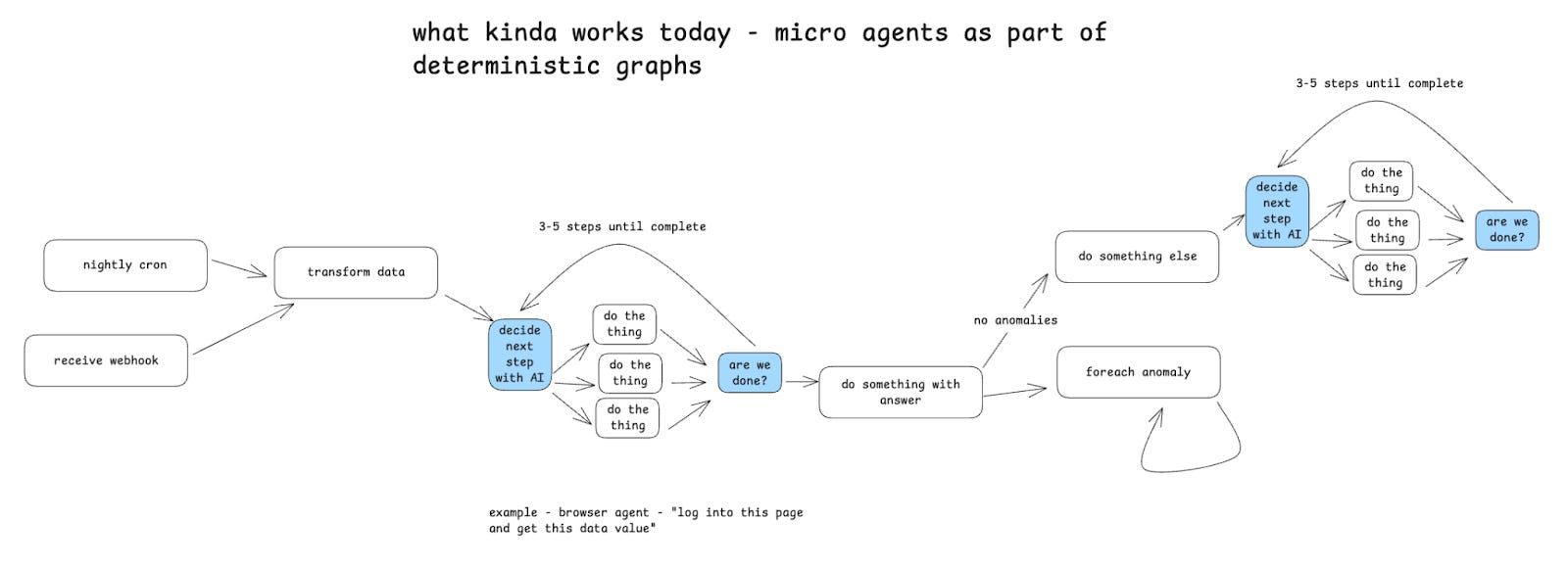
Example of current-day AI agent workflows with micro agents.
Some systems utilize ‘micro agents’ to automate tasks with AI.
Why Multi-Agent Architecture Is on the Rise
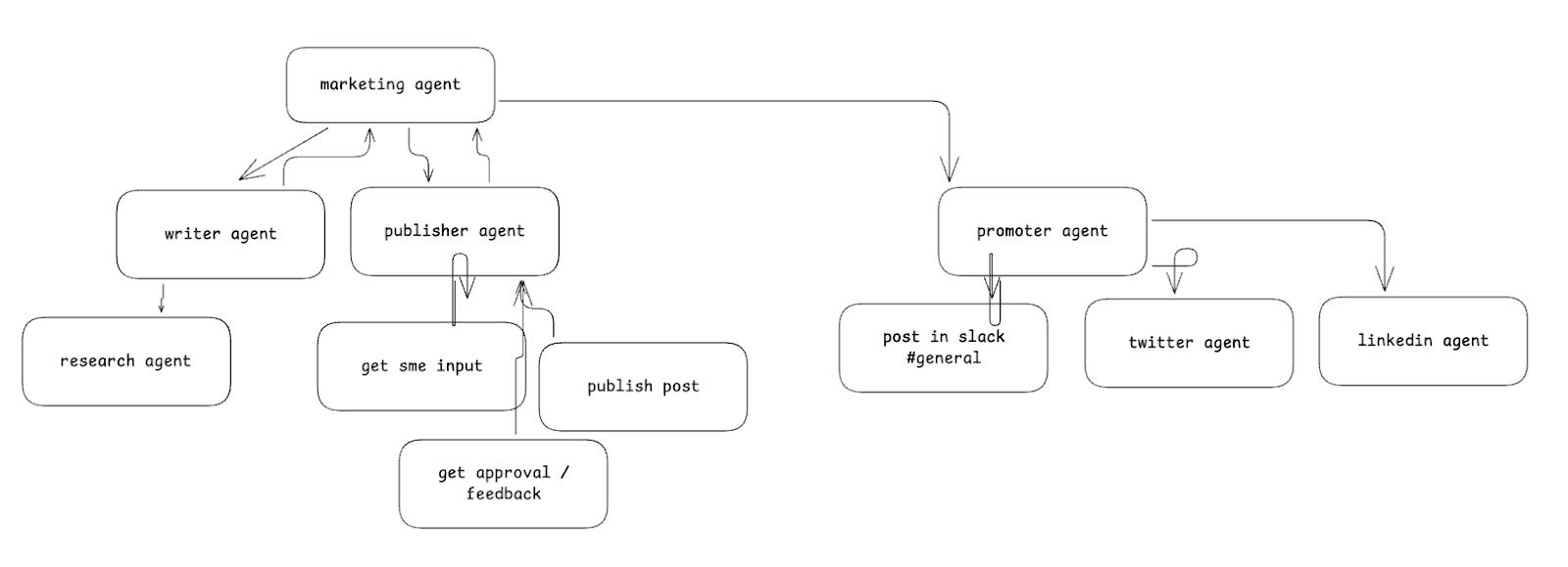
Keeping the context window limited to 3-5 tools and 3-5 steps has proven to be the most effective approach based on observations. This is why multi-agent architecture is gaining popularity; with a hierarchy of agents, they can collaborate on hundreds of steps and utilize hundreds of tools without any single context window becoming too large.
TL;DR: Early “agents” will be LLMs utilizing a few (3-5) tools and/or DAGs for more complex workflows.
Why AI Agents Will Shape the Future—and Why It Matters to You
With RAG-based systems, teams have delivered chatbots that answer customer questions faster and more accurately. RAG addresses both search and understanding challenges. However, if the data isn’t available, the model is prone to hallucination. Current systems perform well at summarizing or rephrasing information.
Assuming models like o1/o3 continue to scale in intelligence, given a dataset with sufficient data points, LLMs will be able to reason thoroughly about the current context and its future implications. This will enable LLMs to automate workflows end-to-end by maintaining a rolling context window as the agent continually evaluates what action to take next. The impact of this will be substantial, even if these agents operate only at a junior level.
Imagine having a fleet of 100 junior marketers at your company. You could use agents to build your business or offload repetitive tasks.
AI 1.0 was read/write through RAG.
AI 2.0 marks the age of action and workflow automation.
Can we trust LLMs to consistently and reliably predict not just the next token, but an entire sequence of say, 10,000 tokens, starting from their current position?
This ultimately comes down to betting on or against scaling laws. Scaling laws suggest that as a model's parameters, data, and compute increase, its performance will also improve. However, all of these factors must scale linearly for this to hold true.
In text, there are basic patterns (e.g., paragraphs, sentences) that become increasingly granular, with progressively abstract and complex associations. As LLMs continue to scale, these patterns will become more emergent and better understood by the models.
The Dario Amodei podcast with Lex Fridman prompted me to reflect on a few essential questions surrounding scaling laws.
Scaling laws – what if we run out of QUALITY data?
One challenge in training large language models (LLMs) is the availability of high-quality data. While there is an estimated 64 zettabytes of data on the internet, only a fraction of it meets the standards required for effective model training. For example, ChatGPT is estimated to have been trained on up to 45TB of data, which, while significant, represents a minuscule portion of available digital content.
Thought 1: each enterprise finetunes on their private data
Training private LLM instances on private enterprise data, such as Slack logs or other proprietary sources, may enable models to develop domain-specific patterns beyond their current capabilities.
Thought 2: we can generate synthetic/hybrid synthetic data
Another promising avenue is synthetic data generation. However, purely synthetic data has limitations, particularly when AI-generated content begins to dominate the training pool which has polluted datasets and even caused open-source projects like Wordfreq to be archived. Alexandr Wang and others have suggested hybrid data strategies—combining synthetic data with input from human experts to overcome LLM knowledge limitations.
Thought 3: we can also use human-in-the-loop responses as training data
Human-in-the-loop systems also offer a practical solution. By incorporating manual feedback and using it as post-training data, these systems can iteratively improve model performance while expanding high-quality datasets.
Thought 4: leveraging test-time compute for validation
We can utilize test-time compute to explore multiple approaches to solving a problem. This was an approach that Dylan Patel referred to in the latest BG2 podcast. By executing these solutions in a controlled, functional environment—such as a codebase where outputs are deterministic—we can effectively validate or invalidate the LLM’s responses based on their accuracy and functionality.
Thought 5: training on different modalities to have the model pick up on more patterns
Given the majority of the data being used is text data, there are still many emerging patterns that models could discover if we feed it different modalities like video data.
Scaling laws – it can just stop getting better for no known reason.
This is a possible outcome that some leaders are observing.
Scaling laws – what happens if we run out of compute and energy?
Alternative energy sources, such as fusion energy, could help overcome energy bottlenecks. As for compute, we’ve already observed significant horizontal scaling (e.g., xAI building a 100k H100 cluster). If horizontal scaling reaches its limits, we will likely return to the drawing board to optimize for efficiency. At that point, it becomes a matter of solving an optimization problem.
The Future of Automating Workflows
Here are the three scenarios I envision for the next two years:
Worst case: Model performance stagnates. We rely on workarounds and hacks, using DAGs and traditional workflow automation.
Base case: Models improve incrementally. Workflow automation is still utilized, but to a lesser extent, as better model performance enables routing queries to more tools.
Best case: Models continue to improve at their current pace (or faster), resulting in AGI or near-AGI capable of automating end-to-end workflows or entire jobs.
I believe vertical agents are going to become production-ready soon, and I can envision a future within the next two years where an orchestration layer routes tasks to the appropriate vertical-specific agents.
What do you think? Will fully agentic workflows exist within the next two years, or will scaling laws continue to necessitate traditional workflow automation?
Also, thanks to Srishti and Shreya for an amazing discussion on this topic.
Best,
Paulo
 | A guest post by
|